Motivation
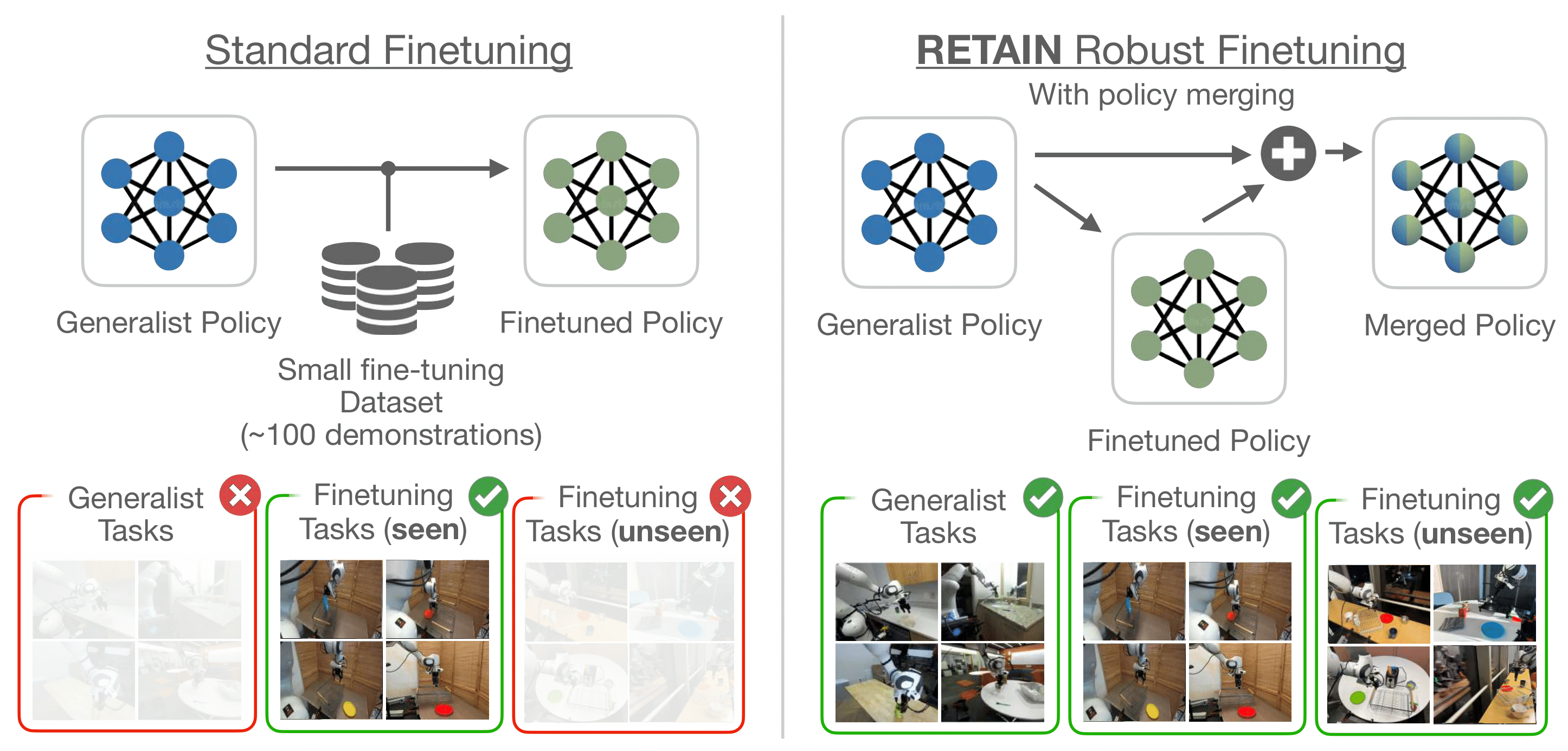
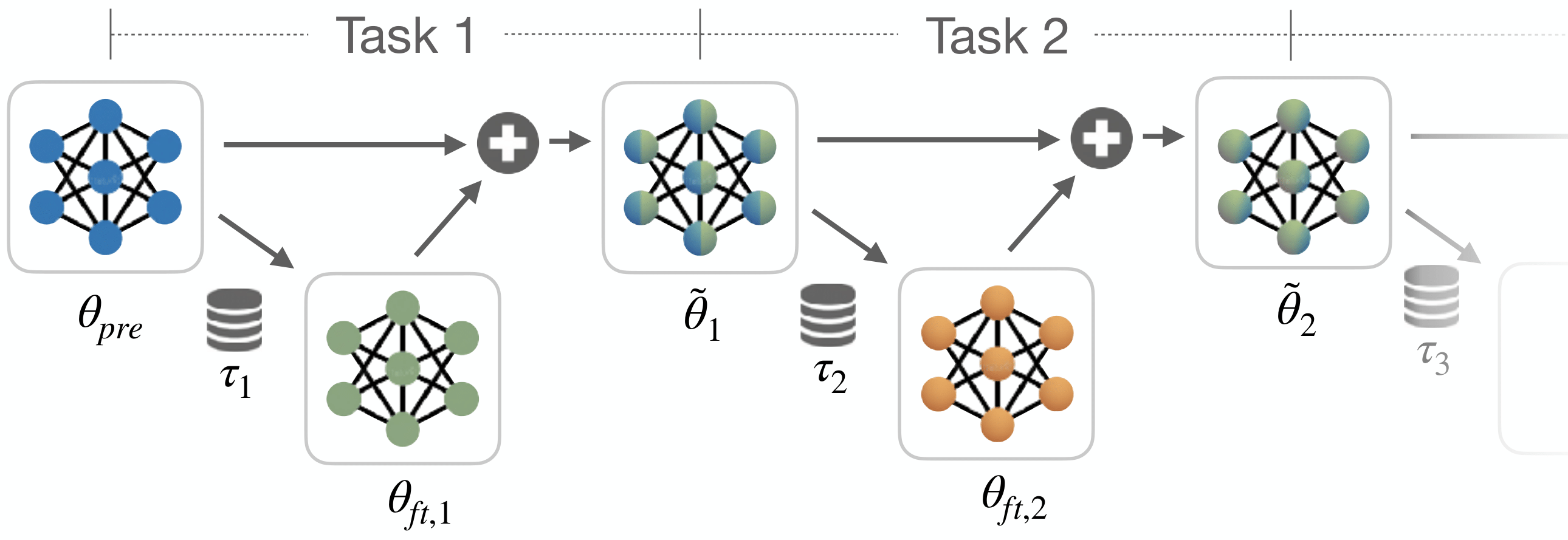
Generalist robot policies have strong capabilities, but still require adaptation for new downstream tasks. Naive finetuning approaches suffer from overfitting and fail to preserve the pretrained model's generality and cannot robustly generalize beyond the narrow conditions present in the limited finetuning dataset. This creates a critical need for methods that can leverage broad pretrained competencies to enable learning generalized skills.
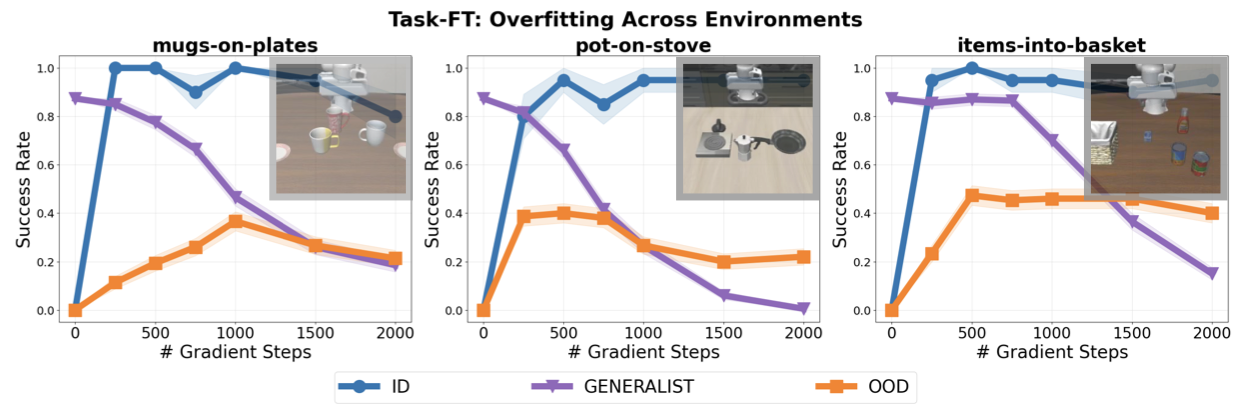
Naive Finetuning Suffers from Overfitting
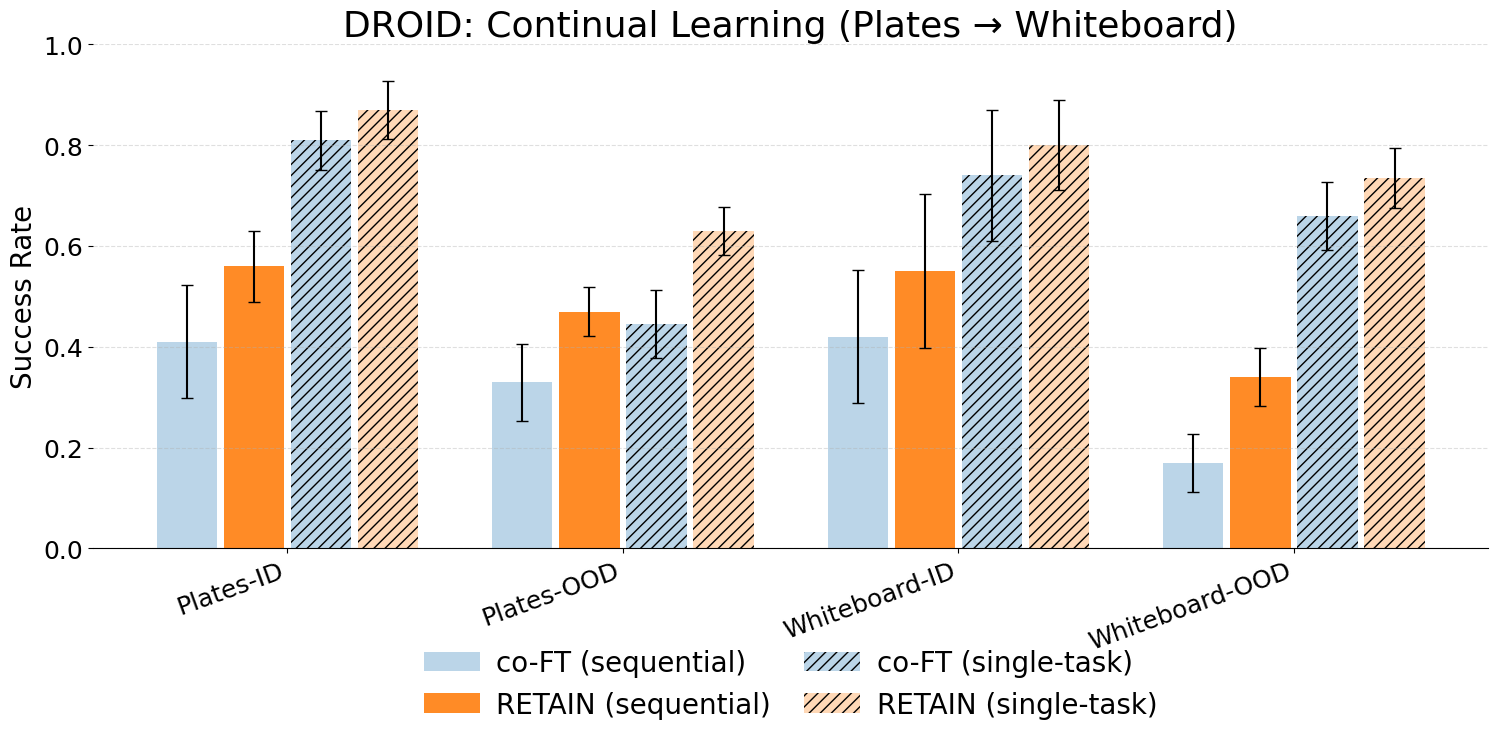
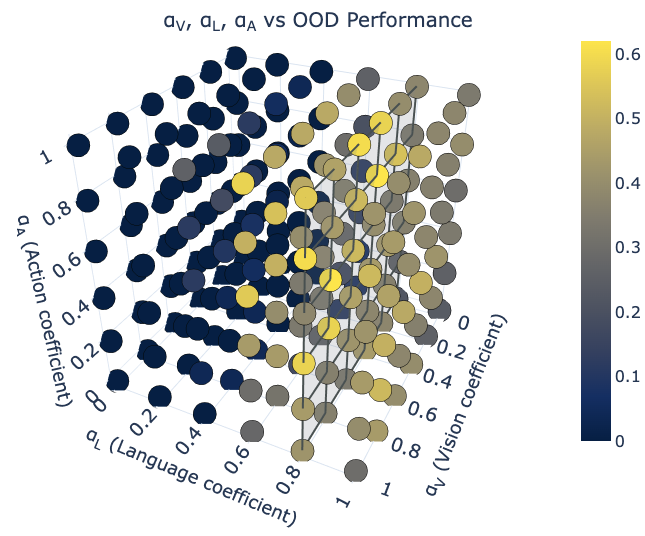
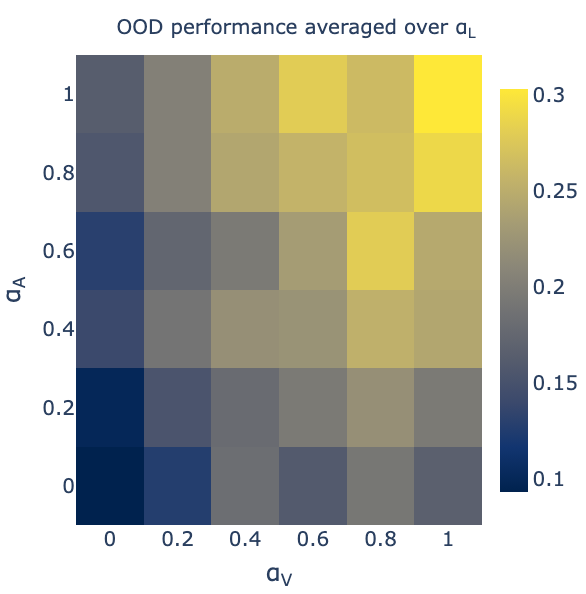
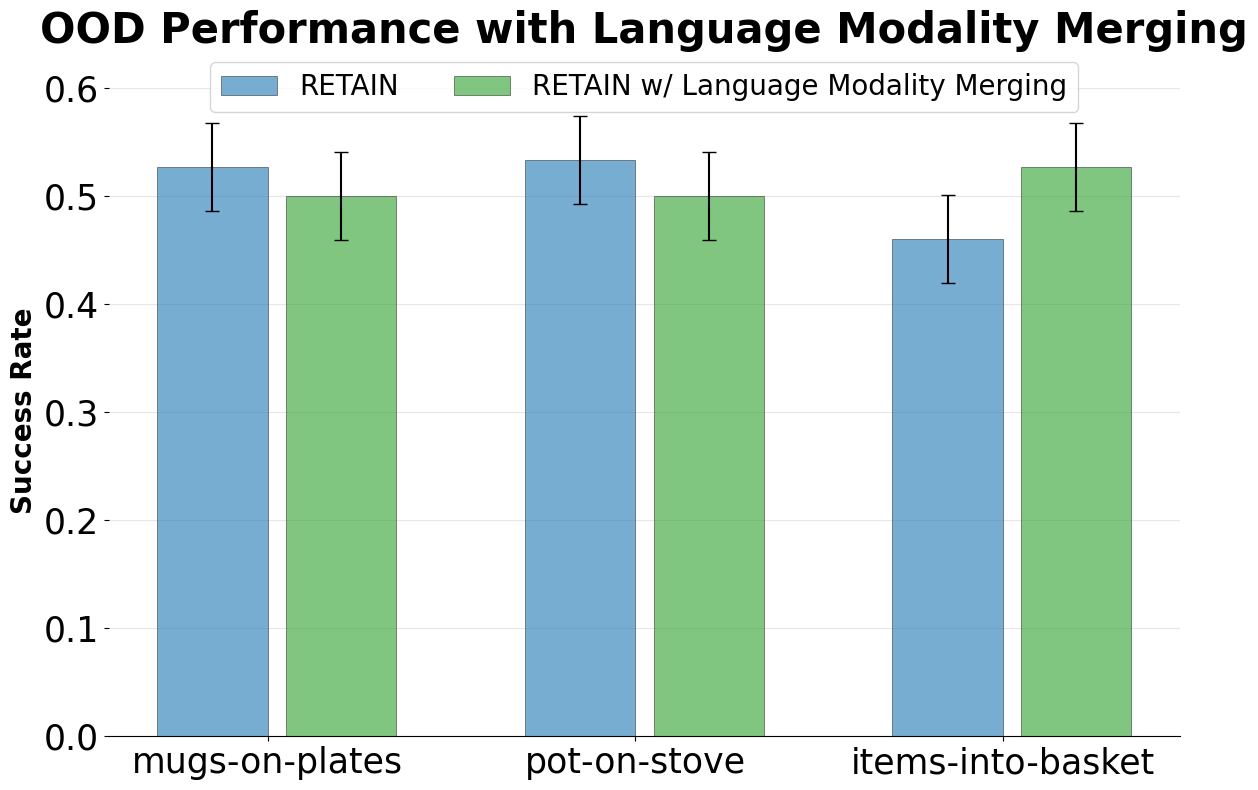
As an example, we finetune a VLA on 3 different LIBERO tasks with standard SFT finetuning, training all parameters of the model on the target task. While the ID performance improves with gradient updates, the Generalist performance drastically degrades as we finetune for longer. This shows that naive finetuning has overfitted the model to the exact dataset distribution, and suffers from catastrophic forgetting of pretraining abilities. Moreover, there is a large gap between ID and OOD performance, suggesting the model has failed to generalize to small variations of the target task because of overfitting.